【イラストAI】コピペ可!Stable Diffusionの簡単な使い方【コードつき】

無料で使えるStable DiffusionというイラストAIが公開されたので使ってみました。
今回はオンライン上で完結するGoogle Colaboratoryを利用する方法を紹介します。
今回の方法を応用することで、ローカルでPython環境上でも利用できます。まずはColab上でどのように動くか試してみると良いと思います。
Contents
必要な環境
- Google Chrome + Googleアカウント (Google Colaboratory上で利用するため)
- Hugging Faceアカウント (トークン利用のため)
モデル利用のためにHugging Faceアカウントに登録する
Stable Diffusionのような画像生成AIは「学習済みモデル」を利用して画像を出力します。つまりStable Diffusionを利用するには「モデル」が別に必要です。
Stable Diffusionで利用できる学習済みモデルは、Hugging Faceで公開されているものを利用することができます。
Hugging Faceのモデル利用規約(Creative ML OpenRAIL-M license)

全部読んで理解する必要がありますが、「出力した画像の権利」については明確です。
モデルを利用して出力した画像については、ユーザー(命令文を出した画像出力者)に権利があるとのことです。モデル権利者から権利を主張されることはないと書かれています。
つまり、Stable Diffusion上でHugging Faceのモデルを利用して出力した画像は、あなたが自分で撮った写真と同じように自由に利用することができます。
ただし、他者に危害を加える目的や虚偽情報の作成や流布、中傷や嫌がらせ、犯罪や法律違反に当たるような利用はしてはなりません。
利用規約に同意できる場合、Hugging Faceのサイトに行ってアカウントを作成して、アクセストークンを作成します。

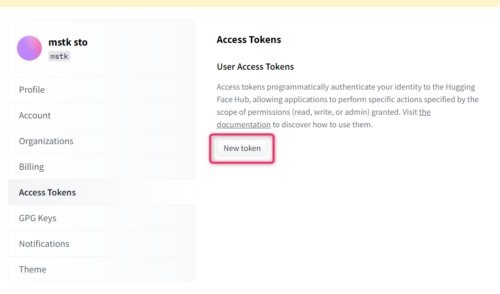 ログイン後、Access Tokenのページから「New token」ボタンを押してトークンを作成します。
ログイン後、Access Tokenのページから「New token」ボタンを押してトークンを作成します。
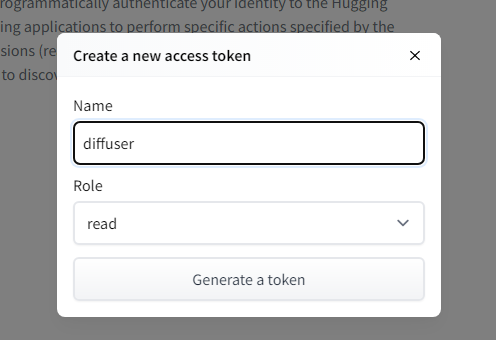
Nameは「diffuser」など、半角で何でもいいので入れます。Roleは「read」です。
入力したら「Generate a token」を押します。
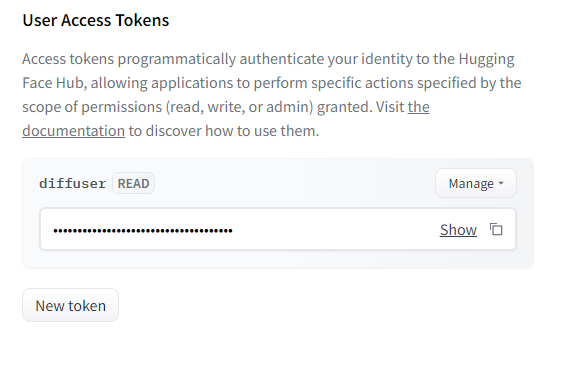
これで新しいトークンが出来ました。
トークンの文字列は絶対に他の人と共有しないでください。
トークンは個人個人で固有の物となっているため、Showを押さないと表示されません。
Stable Diffusion v1-4 Model Cardへのアクセス許可を得る (追記)
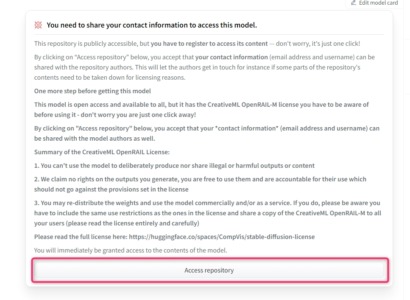
以下のページにてStable Diffusion v1-4 Model Cardに対してもアクセス許可を得る必要がある(Access repositoryを押す)とのことです。

Stable DiffusionをGoogle Colaboratoryで利用する
登録が終わったら、Stable DiffusionをGoogle Colaboratory(以下Colab)で動作させる環境を作ります。
Colabではブラウザ上で簡単にPythonのコーディングと実行が可能です。
Colab経験者の人は以下のサンプルページを見るだけでだいたい分かると思います。

このページに記載されている内容を、自分で新規作成したノートブックで動かしてやればOK。
Colabで新規のノートブックを作る
Googleにログインしたら、新規のGoogle Colaboratoryノートブックを作成します。
Colabのノートブックの仕組み
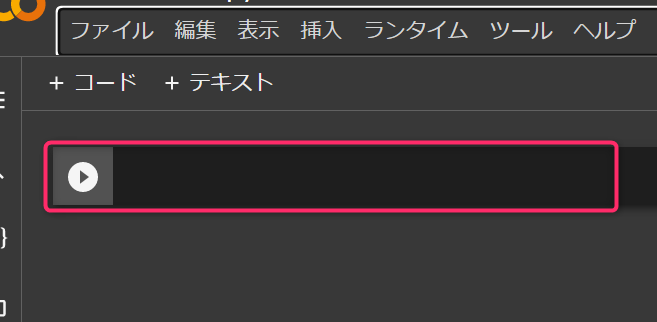 Google Colaboratoryノートブックは、黒い「セル」の部分にPythonのプログラムコードを入力し、Shift+Enterで実行します。
Google Colaboratoryノートブックは、黒い「セル」の部分にPythonのプログラムコードを入力し、Shift+Enterで実行します。
セルの部分だけが実行されるので、何段階かに分けて実行していきます。
ColabでGPUを使えるようにする
最初に、ColabからGPUを使えるようにします。
ここで利用するGPUはあなたのPCに搭載されるGPUではなく、Google Colaboratoryが提供するサーバー側のGPUです。
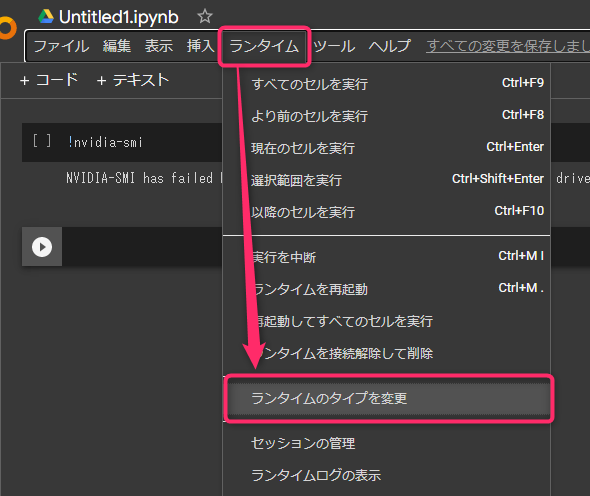 メニューの「ランタイム」→「ランタイムのタイプを変更」を選びます。
メニューの「ランタイム」→「ランタイムのタイプを変更」を選びます。
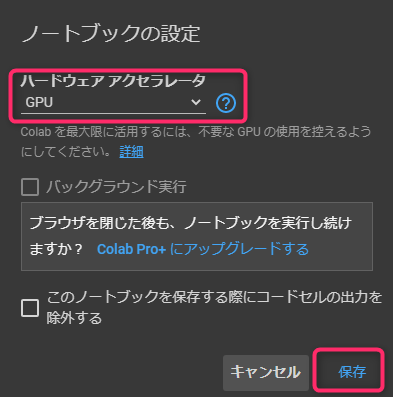 ハードウェアアクセアレータを「GPU」にして保存します。
ハードウェアアクセアレータを「GPU」にして保存します。
セルに以下を入力して、Shift+Enterで実行します。
!nvidia-smi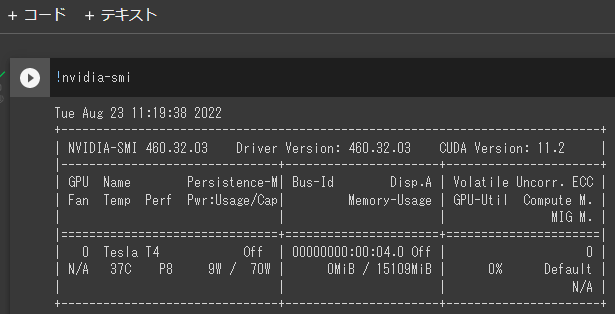
上記の感じでグラフィックボードの情報が取れればOK。
Stable Diffusionの初期設定
ここからは、以下に示すコードをそれぞれ新しいセル(黒い部分)に入力をしていき、Shift+Enterで順に実行していきます。
!pip install diffusers==0.2.4
!pip install transformers scipy ftfy
!pip install "ipywidgets>=7,<8"
from google.colab import output
output.enable_custom_widget_manager()
モデル利用トークンの入力
from huggingface_hub import notebook_login
notebook_login()これを入力して実行すると、Hugging Faceのトークンを入力する画面が出てきます。
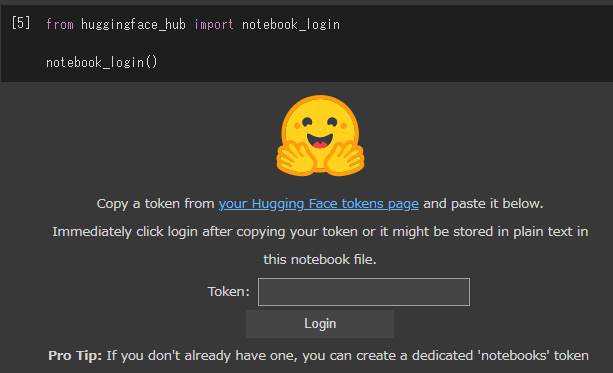
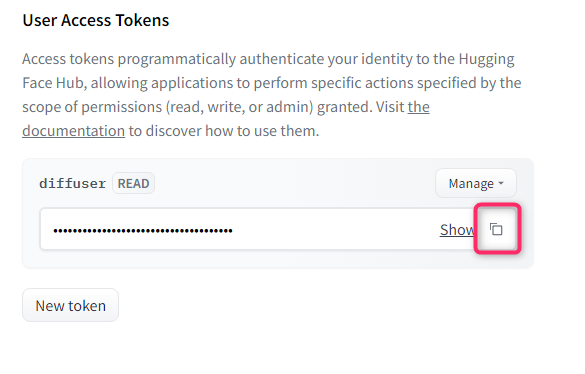 ここで、最初に作成したAccess Tokenのページでコピーボタンを押してトークンをコピーし
ここで、最初に作成したAccess Tokenのページでコピーボタンを押してトークンをコピーし
 Colab側にペーストし、Loginを押します。
Colab側にペーストし、Loginを押します。
 「Login successful」が表示されればOK。
「Login successful」が表示されればOK。
StableDiffusionPipelineのインストール
import torch
from diffusers import StableDiffusionPipeline
# make sure you're logged in with `huggingface-cli login`
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token=True)
初回はダウンロードが行われ、ちょっと時間がかかります。
GPUへの接続
pipe = pipe.to("cuda")
指示文(prompt)の作成と書き出し
5枚の画像を表示する
以下をセルに入力して実行すると連続して5枚の画像が出力されます。
from torch import autocast
from IPython.display import display
#import matplotlib.pyplot as plt
prompt = "a photograph of an astronaut riding a horse"
for i in range(5):
with autocast("cuda"):
image = pipe(prompt)["sample"][0] # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
display(image)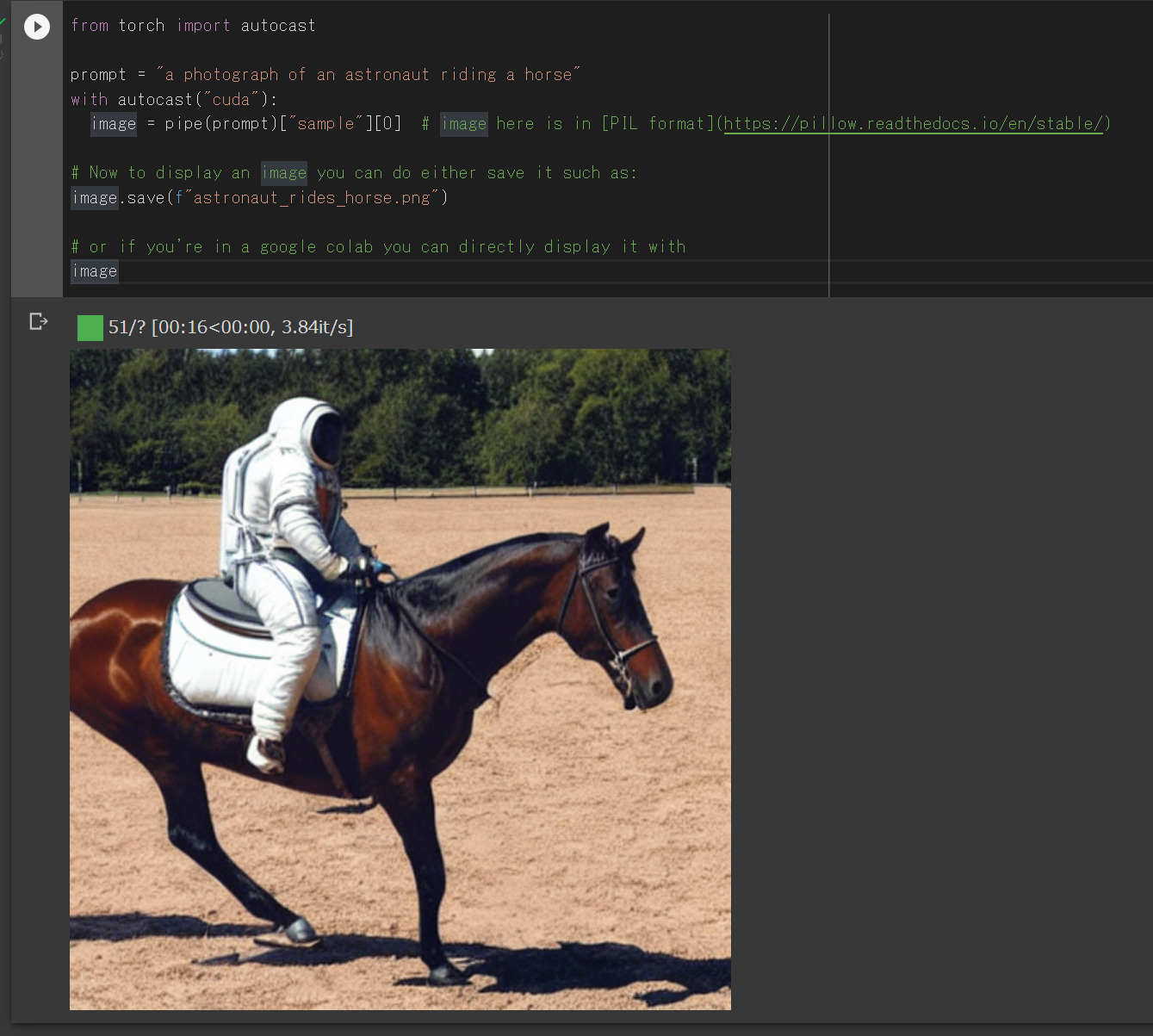
promptのところに「何を書かせたいか」を英語で書く
prompt = "a photograph of an astronaut riding a horse"
この部分が画像出力の命令文になっています。上記の例だと「1頭の馬に乗った宇宙飛行士の1枚の写真」というような意味です。
ダブルクォーテーションの中を英語で自由に書き直してみてください。 たとえば最後に at moonをつけて変化を見てみましょう。
from torch import autocast
from IPython.display import display
#import matplotlib.pyplot as plt
prompt = "a photograph of an astronaut riding a horse at moon"
for i in range(5):
with autocast("cuda"):
image = pipe(prompt)["sample"][0] # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
display(image)promptの内容を変えてもう一度出力したい場合、このセルだけを再実行(Shift+Enter)すればOKです。

月面っぽい背景になりました。
promptのコツなどは色々なサイトで紹介されています。

真っ黒で出ない場合はNSFWな画像が出そうな時
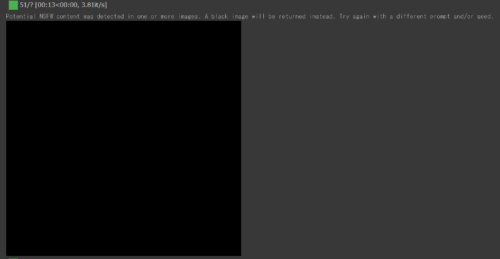
稀にこんな感じで「Potential NSFW content was detected in one or more images. A black image will be returned instead. Try again with a different prompt and/or seed.」というワードとともに、真っ黒な画像が生成されることがあります。
これは、利用規約に違反しそうな画像が出力されそうになった場合のセーフティーが発動しています。
もし黒画像しか連続で出力されない場合はpromptのワードが悪いので、別の文言に変えてください。

記事の内容は執筆、更新日時時点の情報であり、現在は異なっている場合があります。 記載されている会社名・製品名・システム名などは、各社の商標、または登録商標です。
【今日のおすすめ】
【auひかり】最大10Gbpsの超高速通信!最大126,000円還元キャンペーンキャッシュバックで初期工事費も実質無料!


関連記事
 無駄を省いたStable Diffusion Web UIの導入方法。多機能なWindowsローカルGUI環境 Posted in Stable Diffusion
無駄を省いたStable Diffusion Web UIの導入方法。多機能なWindowsローカルGUI環境 Posted in Stable Diffusion ポーズから簡単に画像生成!Stable Diffusion + ControlNetの使い方 Posted in Stable Diffusion
ポーズから簡単に画像生成!Stable Diffusion + ControlNetの使い方 Posted in Stable Diffusion Stable Diffusionの推奨スペックは?GeForceとRTX搭載PCで検証 Posted in ゲーミングPC・レビュー
Stable Diffusionの推奨スペックは?GeForceとRTX搭載PCで検証 Posted in ゲーミングPC・レビュー GUIで動くStable Diffusionのまとめ【ローカル動作】 Posted in ソフトウェア
GUIで動くStable Diffusionのまとめ【ローカル動作】 Posted in ソフトウェア 【イラストAI】ノベルゲーム風のデモを作ってみた【Stable Diffusion】 Posted in ソフトウェア
【イラストAI】ノベルゲーム風のデモを作ってみた【Stable Diffusion】 Posted in ソフトウェア